6 Distributed Computing models
The World of big clusters and complex message passing
7 Map-Reduce
7.1 The (real) beating Heart of Big Data
Map\rightarrow{}Reduce patern is the most common pattern to process data in (real) Big Data.
. . .
It is heavily used by Google, Facebook, and IBM.
. . .
Hadoop from Apache is a popular Map-Reduce framework (also called MapReduce in the Hadoop framework, not to be confused with the more general Map\rightarrow{}Reduce Pattern).
. . .
Hadoop is backed by a HDFS (Hadoop Distributed File System) and a YARN (Yet Another Resource Manager)
- HDFS is a distributed file system (a file system that is distributed across a cluster of computers)
- YARN is a resource manager (a program that manages the resources of a cluster)
7.2 Split-Apply-Combine pattern
- Split:
- Split the data into smaller pieces
- Apply:
- Process the data in the pieces
- Combine:
- Merge the results
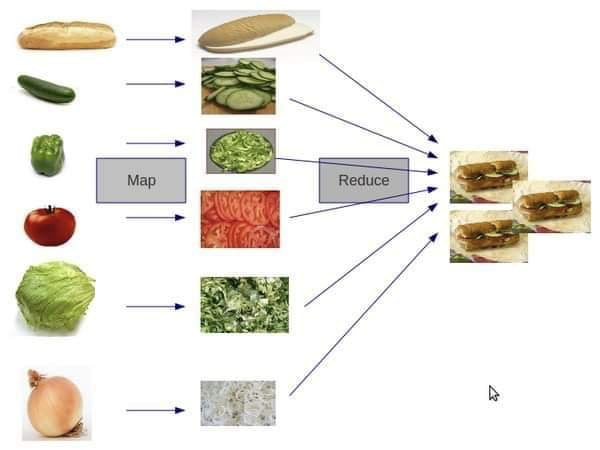
7.3 Map
Map takes one pair of data with a type in one data domain, and returns a list of pairs in a different domain:
Map(k1,v1) → list(k2,v2)
\Longrightarrow heavily parallelized
7.4 Reduce
The values associated from the same key are combined.
The Reduce function is then applied in parallel to each group, which in turn produces a collection of values in the same domain:
Reduce(k2, list (v2)) → list((k3, v3))
7.5 Schema

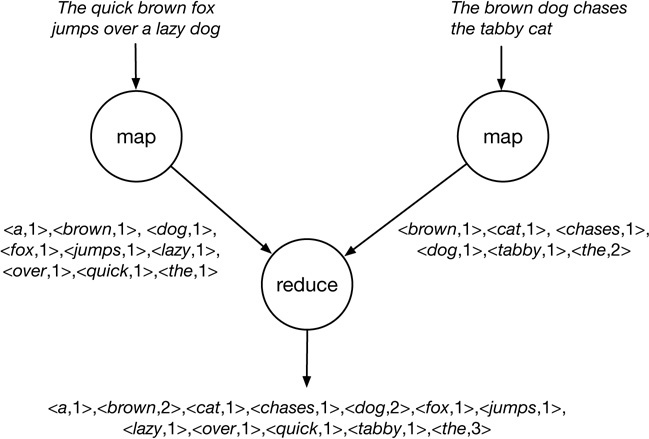
7.6 Canonical example : Word Count, I
The canonical MapReduce example counts the appearance of each word in a set of documents
def map(name, document):
// name: document name
// document: document contents (list of words)
for word in document:
emit (word, 1)
def reduce(word, partialCounts):
// word: a word
// partialCounts: a list of aggregated partial counts
sum = 0
for pc in partialCounts:
sum += pc
emit (word, sum)7.7 Canonical example : Word Count, II
7.8 Spark, spiritual son of MapReduce
Spark is widely used for machine learning on scalable data sets (faster than MapReduce by an order of magnitude).
. . .
Spark is largely inspired by the MapReduce pattern but extends it by using a distributed graph rather than a “linear” data flow like Map\rightarrow{}Reduce.
\Longrightarrow Complex disbributed computing.
. . .
Spark emphasizes ease of use of the cluster ressources in a simple and functional way
7.9 Spark, code example : Word Count
text_file = sc.textFile("hdfs://...")
counts = text_file.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
counts.saveAsTextFile("hdfs://...")7.10 Spark, another example : machine learning
# Every record of this DataFrame contains the label and
# features represented by a vector.
df = sqlContext.createDataFrame(data, ["label", "features"])
# Set parameters for the algorithm.
# Here, we limit the number of iterations to 10.
lr = LogisticRegression(maxIter=10)
# Fit the model to the data.
model = lr.fit(df)
# Given a dataset, predict each point's label,
# and show the results.
model.transform(df).show()8 Message-Passing Patterns
At the heart of any distributed computing system is the message-passing pattern.
Processes are message-passing each other over a network (or a shared memory).
8.1 Schema
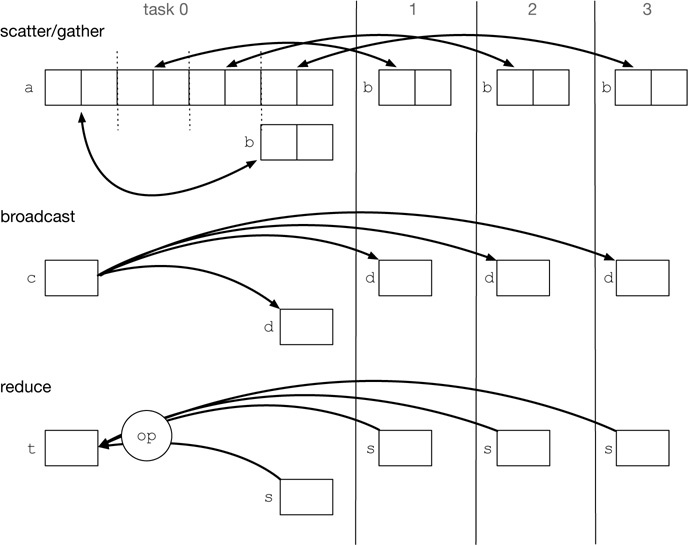
8.2 Main message-passing functions
- Scatter
-
partition the data into smaller pieces and send them to the different processes
- Gather
-
collect the data from the different processes and merge them.
- Broadcast
-
Send the same data to all the processes.
- Reduce
-
Merge the data from all the processes and produce a single result.