3 Advanced concepts in parallel programming
More foray inside the parallel programming
4 Why parallel computing
4.1 Trend over ~50years
- Moore’s Law (doubling the transistor counts every two years) is live
- Single thread performance hit a wall in 2000s
- Along with typical power usage and frequency
- Number of logical cores is doubling every ~3 years since mid-2000

4.2 Computing units
- CPU :
- 4/8/16+ execution cores (depending on context, laptop, desktop, server)
- Hyperthreading (Intel) or SMT (AMD), x2
- Vector units (multiple instructions processed on a vector of data)
- GPU computing : 100/1000 “simple” cores per card
4.3 The reality
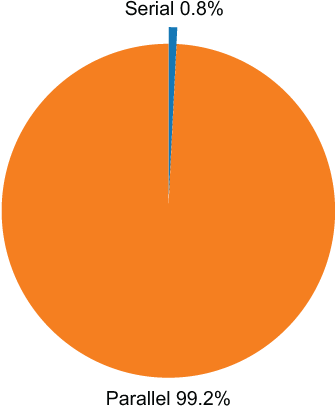
0.08\% = \frac{1}{16 * 2 (cores + hyperthreading) * \frac{256 (bitwide vector unit}{64(bit double)} = 128}
5 Benefits of parallel computing
5.1 Faster for less development
\frac{S_{up}}{T_{par}} \gg \frac{S_{up}}{T_{seq}}
Ratio of speedup improvment S_{up} over time of development (T_{seq|par}) comparison.
From a development time perspective, return on investment (speedup) is often several magnitudes of order better than pure “serial/sequential” improvment.
5.2 Scaling
Simple “divide and conquer” strategies in parallel programming allow to handle data with previously almost untractable sizes and scale before.
5.3 Energy efficiency
This is a huge one, in the present context 😬
Difficult to estimate but the Thermal Design Power (TDP), given by hardware manufacturers, is a good rule of thumb. Just factor the number of units, and usual proportionality rules.
5.4 Energy efficiency, a bunch of CPUs
Example of “standard” use : 20 16-core Intel Xeon E5-4660 which is 120~W of TDP
P = (20~Processors) * (120~W/~Processors) * (24~hours) = 57.60~kWhrs
5.5 Energy efficiency, just a few (big) GPUs
A Tesla V100 GPU is of 300~W of TDP. Let’s use 4 of them.
P = (4~GPUs) * (300~W/~GPUs) * (24~hours) = 28.80~kWhrs
\Longrightarrow half of the power use
6 Laws
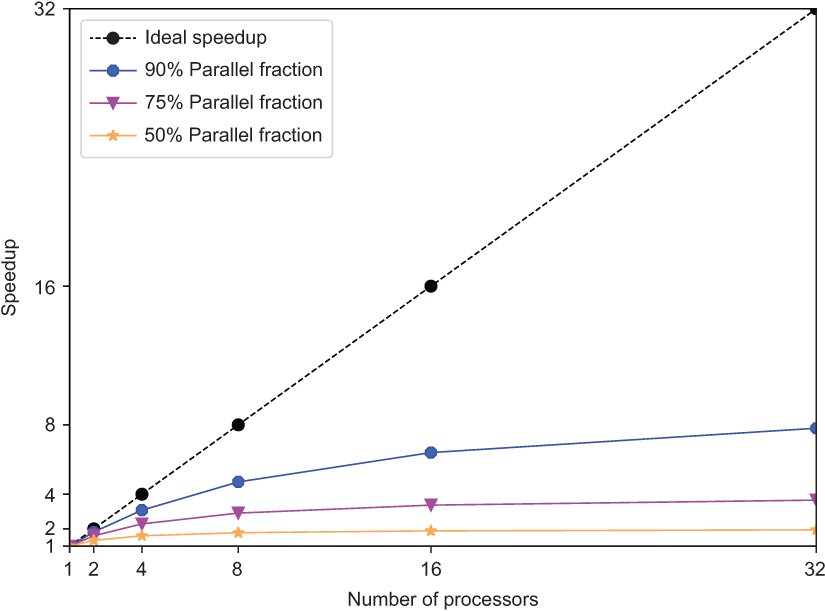
6.1 Asymtptote of parallel computing : Amdahl’s Law
If P and S is the parallel (resp. serial) fraction of the code and N the number of computing units:
S_{up}(N) \le \frac{1}{S+\frac{P}{N}}
6.2 Asymtptote of parallel computing : Amdahl’s Law, Graphic
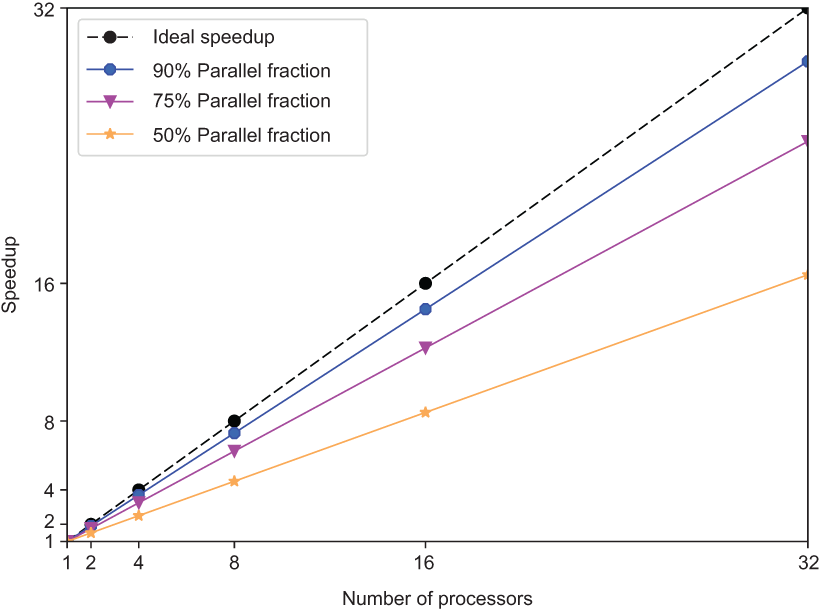
6.3 More with (almost) less : the pump it up approach

When the size of the problem grows up proportionnaly to the number of computing units.
S_{up}(N) \le N - S*(N-1)
where N is the number of computing units and S the serial fraction as before.
6.4 More with (almost) less : graphic
6.5 Strong vs Weak Scaling, definitions
- Strong Scaling
-
Strong scaling represents the time to solution with respect to the number of processors for a fixed total size.
- Weak Scaling
-
Weak scaling represents the time to solution with respect to the number of processors for a fixed-sized problem per processor.
6.6 Strong vs Weak Scaling, schemas
┌────────────────────────────────────┐
│ 1000 │
│ ┌───────────────────┐ │
│ │ │ │ 1 processor
│ │ │ │
│ │ │ │
│ 1000 │ │ │
│ │ │ │
│ │ │ │
│ └───────────────────┘ │
│ ┌─────────┐ ┌─────────┐ │
│ │ │ │ │ │
│ 500 │ │ │ │ │
│ │ │ │ │ │
│ └─────────┘ └─────────┘ │
│ 500 │ 4 processors
│ ┌─────────┐ ┌─────────┐ │
│ │ │ │ │ │
│ │ │ │ │ │
│ │ │ │ │ │
│ └─────────┘ └─────────┘ │
│ 250 │
│ ┌────┐ ┌────┐ ┌────┐ ┌────┐ │
│ 250 │ │ │ │ │ │ │ │ │
│ └────┘ └────┘ └────┘ └────┘ │
│ ┌────┐ ┌────┐ ┌────┐ ┌────┐ │
│ │ │ │ │ │ │ │ │ │
│ └────┘ └────┘ └────┘ └────┘ │ 16 processors
│ ┌────┐ ┌────┐ ┌────┐ ┌────┐ │
│ │ │ │ │ │ │ │ │ │
│ └────┘ └────┘ └────┘ └────┘ │
│ ┌────┐ ┌────┐ ┌────┐ ┌────┐ │
│ │ │ │ │ │ │ │ │ │
│ └────┘ └────┘ └────┘ └────┘ │
└────────────────────────────────────┘┌───────────────────────────────────────────────────────────┐
│ 1000 │
│ ┌─────────┐ │
│ │ │ │
│ 1000 │ ───┼──┐ │
│ │ │ │ │
│ └─────────┘ │ │
│ 1000 │ │
│ ┌─────────┐ ┌────┼────┐ │
│ │ │ │ │ │ │
│ 1000 │ │ │ │ │ │
│ │ │ │ │ │ │
│ └─────────┘ └────┼────┘ │
│ ┌─────────┐ ┌────┼────┐ │
│ │ │ │ │ │ │
│ │ │ │ │ │ │
│ │ │ │ │ │ │
│ └─────────┘ └────┼────┘ │
│ │ 1000 │
│ ┌─────────┐ ┌─────────┐ ┌────┼────┐ ┌─────────┐ │
│ │ │ │ │ │ │ │ │ │ │
│ │ │ │ │ │ ▼ │ │ │1000 │
│ │ │ │ │ │ │ │ │ │
│ └─────────┘ └─────────┘ └─────────┘ └─────────┘ │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │ │ │ │ │ │ │ │ │
│ │ │ │ │ │ │ │ │ │
│ │ │ │ │ │ │ │ │ │
│ └─────────┘ └─────────┘ └─────────┘ └─────────┘ │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │ │ │ │ │ │ │ │ │
│ │ │ │ │ │ │ │ │ │
│ │ │ │ │ │ │ │ │ │
│ └─────────┘ └─────────┘ └─────────┘ └─────────┘ │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │ │ │ │ │ │ │ │ │
│ │ │ │ │ │ │ │ │ │
│ │ │ │ │ │ │ │ │ │
│ └─────────┘ └─────────┘ └─────────┘ └─────────┘ │
└───────────────────────────────────────────────────────────┘7 Types of parallelism
7.1 Flynn’s taxonomy
| Simple Instruction | Multiple Instructions | |
|---|---|---|
| Simple Data |  |
 |
| Multiple Data |  |
 |
7.2 A different approach
| Parallelism level | Hardware | Software | Parallelism extraction |
|---|---|---|---|
| Instruction | SIMD (or VLIW) | Intrinsics | Compiler |
| Thread | Multi-core RTOS | Library or language extension | Partitioning/Scheduling (dependency control) |
| Task | Multi-core (w/o RTOS) | Processes (OS level) | Partitioning/Scheduling |
7.3 Multi-processing vs Multi-threading
Main Process
┌─────────────┐
│ │
│ CPU │
├─────────────┤
│ │
│ Memory │
└─┬────┬────┬─┘
│ │ │
│ │ │
┌───────────┘ │ └───────────┐
│ │ │
┌──────▼──────┐ ┌──────▼──────┐ ┌──────▼──────┐
│ │ │ │ │ │
│ CPU │ │ CPU │ │ CPU │
├─────────────┤ ├─────────────┤ ├─────────────┤
│ │ │ │ │ │
│ Memory │ │ Memory │ │ Memory │
└─────────────┘ └─────────────┘ └─────────────┘
Process 1 Process 1 Process 1┌──────────────────────────────────────┐
│ MAIN PROCESS │
│ │
│ │
│ ┌──────────┐ │
│ │ │ │
│ │ CPU │ ┌───────────┐ │
│ │ │ │ │ │
│ └──────────┘ │ Memory │ │
│ │ │ │
│ └───────────┘ │
│ │
│ │
│ │
│ ┌─┐ ┌─┐ ┌─┐ │
│ │┼│ │┼│ │┼│ │
│ │┴│ │┴│ │┴│ │
│ ▼▼▼ ▼▼▼ ▼▼▼ │
│ Thread 1 Thread 2 Thread 3 │
│ ┌─┐ ┌─┐ ┌─┐ │
│ │┼│ │┼│ │┼│ │
│ │┴│ │┴│ │┴│ │
│ ▼▼▼ ▼▼▼ ▼▼▼ │
│ │
└──────────────────────────────────────┘| Multi-processing | Multi-threading | |
|---|---|---|
| Memory | Exclusive | Shared |
| Communication | Inter-process | At caller site |
| Creation overhead | Heavy | Minimal |
| Concurrency | At OS level | Library/language |
8 Conclusion
- Parallelism is everywhere, but not always easy to exploit
- Two types of scaling with parallelism : strong and weak
- Several types of parallelism : Flynn’s taxonomy, multhreading vs multiprocessing etc.